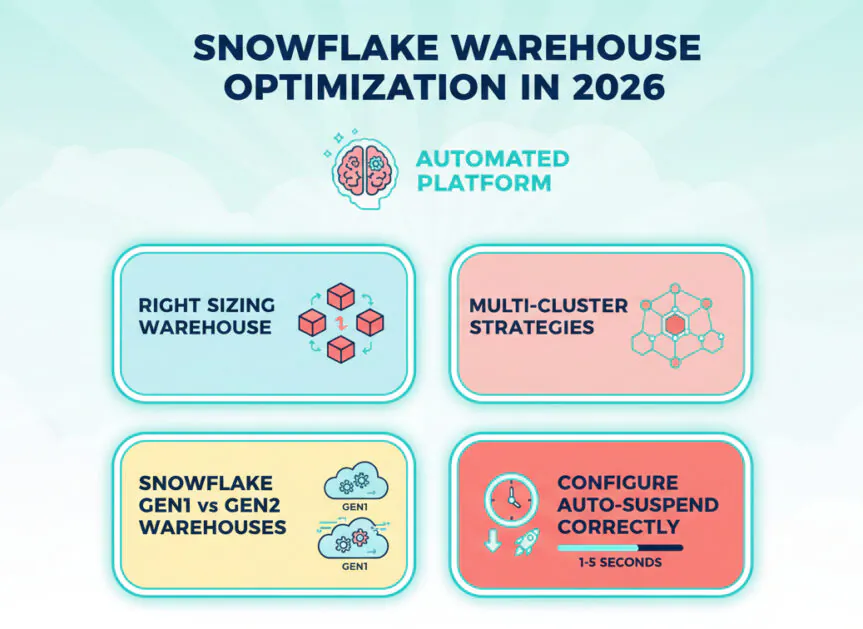
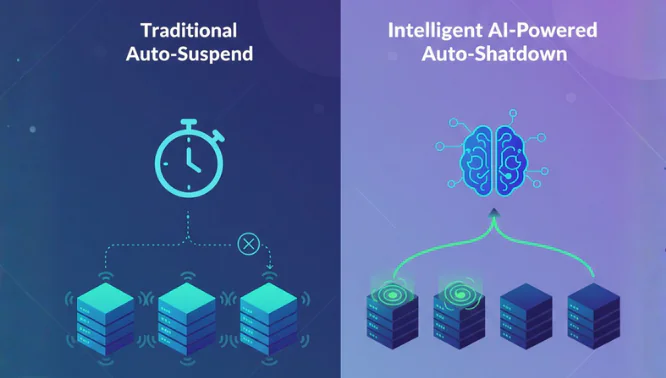
Data Glossary
• Glossary
Auto-Clustering
Batch Processing
Cloud Cost Monitoring
Cloud Data Architecture
Clustered Database
Compute Cost
Continuous Data Cost Control
Cortex AI
Cortex AI SQL
Cortex Analyst
Cortex Code
Cortex Search
Cost Anomaly Detection
Data Credits
Data FinOps
Data Lineage
Data Partitioning
Data Pipeline
Data Process Integrity
Data ROI
dbt Cloud
Descriptive Analytics
Modern Data Stack
Primary Key in Database
Query History
Query Optimization
Query Tags
Runtime Engine
Snowflake Stages
Snowgrid
Time travel
Unity Catalog
• Glossary
Explore essential data management and optimization concepts in the SeeMore Data Glossary. Our curated collection of definitions and explanations helps data and business leaders understand key principles related to data architecture, cost attribution, and performance optimization. Whether you’re looking to refine your data strategy or maximize ROI, our glossary provides clear, concise insights to support informed decision-making. Stay ahead with expert-driven knowledge designed to enhance visibility, efficiency, and the value of your data investment
Prev
Next