The Hidden Cost of Snowflake Cortex AI: A $5K Single-Query Wake-Up Call


TL;DR
Snowflake Cortex AI is transforming how teams work with unstructured data, but it comes with a new cost management challenge: a single query can consume thousands of credits without warning. Unlike traditional warehouse costs, Cortex AI charges are based on token consumption and serving compute, making them difficult to predict and monitor. This guide breaks down the cost structure of every Cortex service, reveals hidden charges like “serving compute” that bill even when idle, and provides actionable frameworks to prevent budget overruns.
Key Insight: One company processed 1.18 billion records with Cortex Functions Query and paid nearly $5K for a single query. The culprit? Token costs, not compute costs.
The $5K Query: Why Snowflake Cortex AI Costs Are Different
Traditional Snowflake cost management focuses on warehouse sizing and query optimization. You know the drill: scale-up vs. scale-out decisions, clustering keys, and query performance tuning.
But Snowflake Cortex AI introduces an entirely new cost paradigm.
The Traditional Model:
SELECT warehouse_size * runtime * credit_rate AS cost FROM your_table;
Predictable. Controllable. Observable.
The Cortex AI Model:
SELECT
(input_tokens + output_tokens) * model * usage
+ serving_compute
+ embedding_compute
+ warehouse_orchestration AS cost
FROM your_table;
Unpredictable. Multi-layered. Opaque.
Real Example: A data team ran a Cortex Functions Query to analyze customer feedback:
- Records processed: 1.18 billion
- Token cost: ~$5,000 in credits
- Query compute cost: Minimal
- Surprise factor: Complete
The team had no resource monitors in place for AI services. No alerts triggered. The bill just appeared.

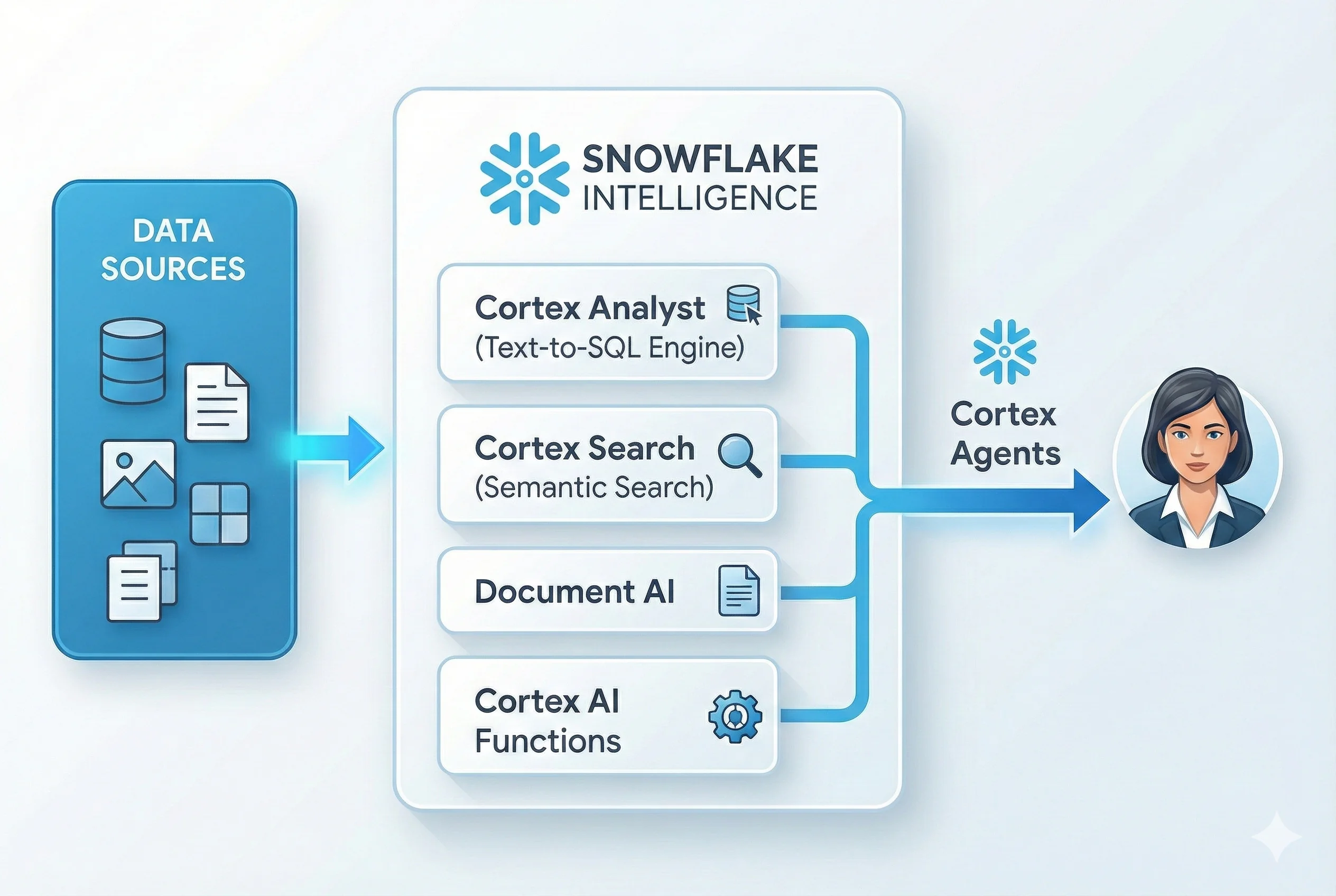
What is Snowflake Cortex AI? A Quick Primer
Before we dive into cost management, let’s establish what we’re dealing with.
The Cortex AI Suite
Snowflake Cortex is a collection of AI features that run inside Snowflake’s security perimeter, meaning:
- ✅ Your data never leaves Snowflake
- ✅ Customer data is never used to train public models
- ✅ Access controlled via familiar RBAC
- ✅ No external API keys or data movement required
The six core services:
- Cortex AI SQL (LLM Functions) – SQL functions for text/image analysis
- Cortex Analyst – Natural language to SQL generation
- Cortex Search – Semantic search over unstructured data
- Document AI – Extract structured data from documents
- Cortex Fine-tuning – Customize models with your data
- Cortex Agents – Orchestrate multi-step AI workflows
Each service has a different cost structure, making unified cost tracking nearly impossible without purpose-built observability.
The Cost Breakdown: Every Cortex Service Explained
1. Cortex AI SQL (LLM Functions): The Token Time Bomb
What It Does
Cortex AI SQL provides functions like:
- AI_COMPLETE() – Generate text completions
- AI_CLASSIFY() – Categorize text or images
- AI_EXTRACT() – Pull structured data from unstructured text
- AI_SENTIMENT() – Analyze sentiment
- AI_SUMMARIZE_AGG() – Aggregate and summarize across rows
- AI_EMBED() – Generate vector embeddings
How You’re Billed
Primary Cost Driver: Tokens
Both input and output tokens are billable for generative functions.
Token Definition:
- Roughly 4 characters = 1 token
- “Hello world” = ~2 tokens
- A typical paragraph = ~100 tokens
- A full product review = ~500 tokens
Example Calculation:
SELECT AI_COMPLETE(‘claude-3-5-sonnet’, review_text) as summary
FROM customer_reviews
WHERE review_date >= ‘2025-01-01’;
If you have:
- 1 million reviews
- Average review length: 500 tokens (input)
- Average summary length: 100 tokens (output)
Token consumption:
- Input: 1M × 500 = 500M tokens
- Output: 1M × 100 = 100M tokens
- Total: 600M tokens
Cost estimate (approximate):
- Large model (Claude-3.5-Sonnet): $0.003/1K input tokens, $0.015/1K output tokens
- Input cost: 500M × $0.003/1K = $1,500
- Output cost: 100M × $0.015/1K = $1,500
- Total: ~$3,000
And this is for a single query.
Monitoring Token Usage
Snowflake provides two Account Usage views:
- CORTEX_FUNCTIONS_USAGE_HISTORY
SELECT
function_name,
model_name,
DATE_TRUNC(‘day’, start_time) as usage_date,
SUM(input_tokens) as total_input_tokens,
SUM(output_tokens) as total_output_tokens,
SUM(credits_used) as total_credits
FROM snowflake.account_usage.cortex_functions_usage_history
WHERE start_time >= DATEADD(day, -7, CURRENT_TIMESTAMP())
GROUP BY function_name, model_name, usage_date
ORDER BY total_credits DESC;
- CORTEX_FUNCTIONS_QUERY_USAGE_HISTORY
— Identify expensive queries
SELECT
query_id,
user_name,
function_name,
model_name,
input_tokens,
output_tokens,
credits_used,
start_time
FROM snowflake.account_usage.cortex_functions_query_usage_history
WHERE start_time >= DATEADD(day, -7, CURRENT_TIMESTAMP())
AND credits_used > 100 — Flag queries over 100 credits
ORDER BY credits_used DESC
LIMIT 50;
Critical Gap: Unlike warehouse resource monitors, there are no native resource monitors for AI services. Teams must build custom alerting.
Learn how real-time anomaly detection prevents cost spikes →
2. Cortex Search Service: The Idle Tax
Cortex Search enables semantic search over unstructured data using natural language queries. But its billing model has a hidden trap.
Cost Component 1: Serving Compute (Always Running)
The Catch: You pay for the serving layer even when no queries are being executed.
Real Example from the Field: A team created a Cortex Search Service for their knowledge base:
- Service created: January 1st
- First query executed: January 15th
- Serving compute charged: Every day from January 1-15
Billing: Charged per gigabyte per month (GB/mo) of uncompressed indexed data, including:
- Your source data
- Vector embeddings (automatically generated)
Example Cost:
- Data size: 50GB uncompressed
- Vector embeddings: ~20GB (EMBED_TEXT_1024)
- Total indexed: 70GB
- Cost: 70GB × $2/GB/mo = $140/month (even with zero queries)
Cost Control Strategy:
— Suspend service when not in use (e.g., during dev)
ALTER SEARCH SERVICE my_search_service SUSPEND;
— Resume when needed
ALTER SEARCH SERVICE my_search_service RESUME;
Best Practice: Only keep services running in production. Suspend dev/test services nightly.
Cost Component 2: Indexing & Embedding Compute
- Virtual Warehouse Compute
A warehouse is required to:
- Refresh the search index
- Run queries against base objects
- Orchestrate embedding jobs
Recommendation: Most services don’t need to be larger than a MEDIUM or LARGE warehouse.
- EMBED_TEXT Token Compute
When you create a Cortex Search Service on text columns, Snowflake automatically embeds the text into vector space using functions like:
- EMBED_TEXT_768 (768-dimension vectors)
- EMBED_TEXT_1024 (1024-dimension vectors)
This process costs credits based on token count.
Incremental Processing: Only applies to new or updated rows (not full re-embedding on every refresh).
Optimizing Indexing Costs
- Set Appropriate TARGET_LAG
CREATE SEARCH SERVICE my_service
ON base_table
TARGET_LAG = ‘1 hour’; — Don’t refresh more often than needed
Default: 1 minute (very expensive for large datasets)
Recommendation: Set to business requirements (hourly, daily, etc.)
- Define Primary Keys
CREATE SEARCH SERVICE my_service
ON base_table (
id AS PRIMARY KEY, — Significantly reduces indexing cost
content_column,
metadata_column
);
Impact: Uses optimized incremental refresh path, reducing latency and cost by 50-70%.
- Minimize Schema Changes
Schema changes trigger full re-indexing, which is expensive. Plan your search column schema carefully before launch.
Learn about data pipeline optimization strategies →
3. Cortex Analyst: Natural Language SQL Generation
Cortex Analyst converts natural language questions into SQL queries against your data.
Example – User asks: “What were our top 3 products by revenue last quarter?”
Cortex Analyst generates:
SELECT product_name, SUM(revenue) as total_revenue
FROM sales
WHERE sale_date >= ‘2025-07-01’ AND sale_date < ‘2025-10-01’
GROUP BY product_name
ORDER BY total_revenue DESC
LIMIT 3;
Cost Structure
Token-based pricing:
- Input tokens: User’s natural language question
- Output tokens: Generated SQL + explanation
- Execution: Normal warehouse compute for running the generated query
Key Insight: The generated SQL query runs on your warehouse, so you pay:
- Cortex Analyst token costs (typically low, <100 tokens per question)
- Warehouse compute for query execution (can be high for complex queries)
Cost Management:
- Monitor generated SQL complexity
- Ensure generated queries are optimized (clustering keys, materialized views)
- Route Analyst queries to appropriately-sized warehouses
Understand true query costs with proper attribution →
4. Cortex Agents: Orchestration Overhead
Preview Feature (as of October 2025)
Cortex Agents orchestrate across structured and unstructured data sources to deliver insights.
How Agents Work
- Planning: Parse request, create execution plan
2. Tool Use: Route to Cortex Analyst (structured) or Cortex Search (unstructured)
3. Reflection: Evaluate results, iterate or generate response
Cost Components
In preview, costs include:
- Cortex Analyst usage (token costs)
- Cortex Search usage (serving + embedding costs)
- Custom tools (warehouse compute for stored procedures/UDFs)
Access Control:
GRANT APPLICATION ROLE SNOWFLAKE.CORTEX_USER TO ROLE data_analyst;
— or
GRANT APPLICATION ROLE SNOWFLAKE.CORTEX_AGENT_USER TO ROLE data_analyst;
Billing Strategy: Since agents orchestrate multiple services, expect multiplicative cost impact. One agent request might trigger:
- 3 Cortex Analyst queries
- 2 Cortex Search requests
- 5 custom tool executions
Cost Control: Implement request-level monitoring and rate limiting.
5. Document AI & Fine-Tuning: Specialized Workloads
Document AI
Extracts structured data from PDFs, images, and documents.
Cost: Based on document size and processing complexity (token-equivalent billing).
Cortex Fine-Tuning
Customizes models with your data for improved domain-specific performance.
Cost Components:
- Training compute (one-time or periodic)
- Inference costs (similar to standard LLM functions)
Recommendation: Only fine-tune if pre-trained models consistently underperform on your specific use case.
Cost Monitoring Framework: Avoiding the $5K Surprise
Since Snowflake doesn’t provide native resource monitors for AI services, you need to build your own.
Daily Cost Monitoring Query
CREATE OR REPLACE VIEW cortex_daily_cost_summary AS
SELECT
DATE_TRUNC(‘day’, start_time) as usage_date,
user_name,
function_name,
model_name,
COUNT(*) as query_count,
SUM(input_tokens) as total_input_tokens,
SUM(output_tokens) as total_output_tokens,
SUM(credits_used) as total_credits,
AVG(credits_used) as avg_credits_per_query,
MAX(credits_used) as max_credits_single_query
FROM snowflake.account_usage.cortex_functions_query_usage_history
WHERE start_time >= DATEADD(day, -30, CURRENT_TIMESTAMP())
GROUP BY usage_date, user_name, function_name, model_name
ORDER BY usage_date DESC, total_credits DESC;
Alert Thresholds
Set up automated alerts for:
- Daily Cost Spike
SELECT *
FROM cortex_daily_cost_summary
WHERE total_credits > 1000 — Threshold based on your budget
AND usage_date = CURRENT_DATE();
- Individual Expensive Query
SELECT query_id, user_name, credits_used
FROM snowflake.account_usage.cortex_functions_query_usage_history
WHERE start_time >= DATEADD(hour, -1, CURRENT_TIMESTAMP())
AND credits_used > 500; — Single query > $500
- Unusual Model Usage
— Detect use of expensive models by unauthorized users
SELECT user_name, model_name, COUNT(*) as usage_count
FROM snowflake.account_usage.cortex_functions_query_usage_history
WHERE start_time >= CURRENT_DATE()
AND model_name IN (‘claude-3-7-sonnet’, ‘mistral-large2’)
GROUP BY user_name, model_name
HAVING usage_count > 0;
Get proactive AI-driven cost alerts →
Cortex Search Query Optimization
Filtering for Cost Efficiency
Cortex Search supports five matching operators on ATTRIBUTES columns:
| Operator | Use Case | Example |
| @eq | Exact match | {“@eq”: {“category”: “electronics”}} |
| @contains | Array membership | {“@contains”: {“tags”: “urgent”}} |
| @gte / @lte | Numeric ranges | {“@gte”: {“price”: 100}} |
| @primarykey | Specific records | {“@primarykey”: [123, 456]} |
Cost Impact: Filtering reduces the search space, lowering token consumption and latency.
Example:
# Without filtering – searches entire index
results = search_service.search(
query=”product reviews about battery life”,
columns=[“review_text”, “rating”],
limit=10
)
# With filtering – searches only relevant subset
results = search_service.search(
query=”product reviews about battery life”,
columns=[“review_text”, “rating”],
filter={“@eq”: {“category”: “laptops”}},
limit=10
)
Customizing Ranking for Performance
Default: Semantic search + reranking (most relevant, but higher cost)
Optimization Options:
- Disable Reranking
SELECT *
FROM search_service
WHERE MATCH(content) AGAINST(‘…’ IN NATURAL LANGUAGE MODE)
ORDER BY MATCH(content) AGAINST(‘…’ IN NATURAL LANGUAGE MODE) DESC;
Benefit: Reduces query latency by 100-300ms
Trade-off: Slightly less relevant results
- Apply Numeric Boosts
SELECT
*,
MATCH(content) AGAINST(‘…’ IN NATURAL LANGUAGE MODE)
+ (click_count * 0.5)
+ (like_count * 0.3) AS relevance_score
FROM search_service
WHERE MATCH(content) AGAINST(‘…’ IN NATURAL LANGUAGE MODE)
ORDER BY relevance_score DESC;
- Apply Time Decay
SELECT
*,
MATCH(content) AGAINST(‘…’ IN NATURAL LANGUAGE MODE)
+ (DATEDIFF(CURRENT_DATE, published_date) * -0.1) AS relevance_score
FROM search_service
WHERE MATCH(content) AGAINST(‘…’ IN NATURAL LANGUAGE MODE)
ORDER BY relevance_score DESC;
Best Practices: Cortex AI Cost Management
1. Start Small, Scale Intentionally
- Pilot with small datasets and inexpensive models
- Measure token consumption patterns
- Only scale after establishing cost baselines
2. Implement Pre-Processing
- Filter data before sending to AI functions
- Chunk large documents intelligently
- Cache common responses
— Filter data before AI processing
SELECT SNOWFLAKE.CORTEX.COMPLETE(‘mistral-7b’, filtered_text) AS ai_response
FROM (
SELECT text_column AS filtered_text
FROM source_table
WHERE length(text_column) < 5000 — Pre-filter large documents
AND status = ‘active’
) subquery;
3. Choose Models Based on Task Complexity
- Simple task (sentiment) → mistral-7b
- Medium task (extraction) → claude-3-5-sonnet
- Complex task (reasoning) → claude-3-7-sonnet
4. Monitor Token Consumption Daily
Create dashboards for:
- Credits used per function
- Credits used per user
- Credits used per model
- Trend analysis (week-over-week)
5. Suspend Idle Search Services
— Automated suspension for dev services
ALTER SEARCH SERVICE dev_search_service SUSPEND;
6. Use Least-Privileged Roles for Service Creation
Never use ACCOUNTADMIN to create Cortex services.
7. Set Realistic TARGET_LAG
Don’t refresh search indexes more frequently than business requirements demand.
8. Define Primary Keys
Reduces indexing costs by 50-70% for Cortex Search.
9. Enable Cortex Guard for Public-Facing Use Cases
Prevents harmful content from reaching users.
10. Implement Custom Alerting
Since no native resource monitors exist, build alerts for:
- Daily cost thresholds
- Single-query cost limits
- Unauthorized model usage
Learn about continuous cost control strategies →
The Future: AI-Driven Cortex Cost Optimization
Just as AI is transforming data operations, it’s also being used to optimize its own costs.
Emerging Patterns:
- Intelligent Model Selection
AI agents analyze query patterns and automatically route to:
- Small models for simple tasks
- Medium models for balanced needs
- Large models only when necessary
- Dynamic Token Budgeting
Systems that allocate token budgets per user/team and enforce limits. - Automatic Query Optimization
AI detects inefficient prompts and rewrites them for lower token consumption while maintaining output quality. - Predictive Cost Forecasting
ML models predict monthly Cortex costs based on usage trends, enabling proactive budget management.
Learn about autonomous data optimization →
Key Takeaways
- Cortex AI costs are fundamentally different from warehouse compute costs—token-based, unpredictable, and multi-layered
- A single query can cost thousands if processing billions of records with expensive models
- Cortex Search charges serving compute even when idle—suspend services when not in use
- Owner’s rights execution can bypass security policies—never use ACCOUNTADMIN for service creation
- Model selection dramatically impacts cost—use small models for simple tasks
- No native resource monitors exist—build custom alerting and monitoring
- Pre-processing and filtering reduce costs by 50-80%—don’t send unnecessary data to AI functions
- Search service optimization saves $2-4K/month—set TARGET_LAG, define primary keys, suspend dev services
What’s Next?
Cortex AI cost management is just one piece of comprehensive Snowflake optimization.
Continue your cost optimization journey:
- Scale-up vs. scale-out warehouse decisions
- Why observability is the root cause of cost problems
- The truth about Snowflake query costs
- Data lineage for cost attribution
Related videos:
Take action:
- Audit your current Cortex AI usage with the queries in this post
- Identify your top 3 cost-driving functions
- Implement token consumption monitoring
- Test cheaper models for simple tasks
- Set up cost alerts
Seemore Data provides real-time visibility into Cortex AI costs alongside traditional warehouse costs, enabling unified cost management. Book a demo to see how comprehensive observability prevents surprise AI bills.
Frequently Asked Questions About Snowflake Cortex AI
How does Snowflake Cortex AI pricing actually work?
Cortex AI uses token-based pricing (input + output tokens for LLMs) plus serving compute charges that run 24/7 for services like Cortex Search, independent of warehouse size. A single query processing millions of records with Claude Sonnet can cost thousands in tokens alone. Seemore Data tracks Cortex AI spend alongside traditional warehouse costs, giving you unified visibility into the full picture—token consumption, serving charges, and warehouse orchestration—attributed to specific users and queries.
Why do Snowflake Cortex AI costs spike without warning?
Unlike warehouses with native resource monitors, Cortex AI has no built-in cost controls or alerts. Teams run “quick tests” processing large datasets with expensive models and discover $5K bills afterward—like one company that paid nearly $5,000 for a single query on 1.18 billion records. Seemore Data’s AI-driven anomaly detection flags unusual Cortex consumption in real time, explaining exactly which query, user, or model caused the spike before it compounds into a budget problem.
What’s the hidden cost in Snowflake Cortex Search pricing?
Cortex Search charges serving compute continuously based on indexed data size (GB/month), even with zero queries running—an “idle tax” unique among Snowflake services. If you index 50GB with 20GB of embeddings, you pay for 70GB monthly whether you search once or a thousand times. Seemore Data alerts you to idle search services consuming credits unnecessarily and helps you suspend dev services or adjust TARGET_LAG settings to align refresh frequency with actual business needs.
How can I control Snowflake Cortex pricing without blocking innovation?
Start with smaller models for simple tasks (mistral-7b costs 96% less than claude-4-opus on 10M tokens), filter data before AI functions, and materialize results to avoid reprocessing. The key is visibility into who runs what, how often, and at what cost—not restriction. Seemore Data provides per-team token budgets, cost attribution by query and user, and proactive alerts that enable teams to experiment confidently while keeping spend predictable and tied to business value.
Can Snowflake Cortex AI be monitored with native tools?
Snowflake provides Account Usage views like CORTEX_FUNCTIONS_USAGE_HISTORY, but these require custom queries, manual interpretation, and no proactive alerting. You need separate monitoring for tokens, serving compute, and embedding costs across different AI services. Seemore Data centralizes all Cortex AI costs (LLM functions, Search, Analyst, Document AI) in a unified dashboard with automated anomaly detection, eliminating the manual work of building custom monitoring while providing the context needed to understand and control AI workload spend.
What drives the biggest Snowflake Cortex AI cost overruns?
Large batch processing with premium models, high-token prompts that generate verbose outputs, Cortex Search services left running in dev environments, and reprocessing AI results instead of materializing them. These patterns often hide until the bill arrives. Seemore Data highlights waste patterns early—like search services indexing every minute when hourly would suffice, or queries repeatedly calling AI_COMPLETE on the same data—and flags risky usage with specific recommendations before costs compound.
Is Snowflake Cortex AI production-ready for cost-sensitive workloads?
Yes, with proper guardrails. Production success depends on choosing appropriate models for task complexity, implementing incremental indexing with primary keys (saving 50-70% on Cortex Search refreshes), and establishing token budgets per team or use case. Seemore Data helps teams scale Cortex AI safely by connecting AI spend to business context, detecting anomalies immediately, and enabling cost-aware governance without slowing experimentation or innovation.
How does Seemore Data solve Snowflake Cortex AI cost management?
Seemore Data provides unified visibility across traditional warehouse compute and all Cortex AI services in a single dashboard, tracking token consumption, serving charges, and embedding costs. It attributes every dollar to specific queries, users, teams, and pipelines with full lineage context. Real-time anomaly detection flags spikes before they hit your budget, explaining root causes in natural language—like “Search service running in dev since Jan 1st” or “Query processing 10x normal token volume.” Teams manage Cortex AI proactively instead of reacting to billing surprises.