Snowflake Adaptive Warehouses Change the Interface. They Do Not Remove the Engineering Problem.


For years, Snowflake warehouse tuning lived inside a familiar triangle: size, concurrency, and cost.
If performance was bad, teams sized up.
If the bill was too high, teams sized down.
If queues appeared, they added clusters or changed the scaling policy. It was not elegant, but it was understandable.
Adaptive Warehouses change that model.
They remove warehouse sizing, multi-cluster settings, Query Acceleration configuration, and suspend/resume semantics from the operator surface. In their place, Snowflake exposes a much smaller interface.
That is a real product improvement.
But it is important to be precise about what actually changed.
Adaptive Warehouses simplify the interface. They do not eliminate the engineering problem.
Table of Contents
- What Is Snowflake Adaptive Compute and What Actually Changed?
- Why this matters for Snowflake warehouse tuning
- What Snowflake Adaptive Warehouses Improve
- But here is the part that matters even more
- This is where Snowflake Adaptive Warehouses can get confusing
- The current blind spot
- My take
- FAQ
What Is Snowflake Adaptive Compute and What Actually Changed?
The old model asked engineers to choose infrastructure directly.
- Pick a warehouse size.
- Decide how many clusters to allow.
- Tune concurrency behavior.
- Manage cost side effects.
- Repeat.
The new model asks engineers to express their intent, which is actually really cool.
How much performance headroom should a single query be allowed to consume?
How much throughput should the system tolerate before queueing?
That is a better abstraction.
Instead of manually forcing a mixed workload through a single static warehouse shape, Snowflake now allocates compute resources more dynamically based on the query and the policy envelope surrounding it.
This is the real shift.
Not “serverless”, “AI for warehouses”, or “no tuning” – this:
Snowflake is moving from fixed infrastructure selection to workload-aware resource allocation.
That is, without a doubt right direction!
Why this matters for Snowflake warehouse tuning
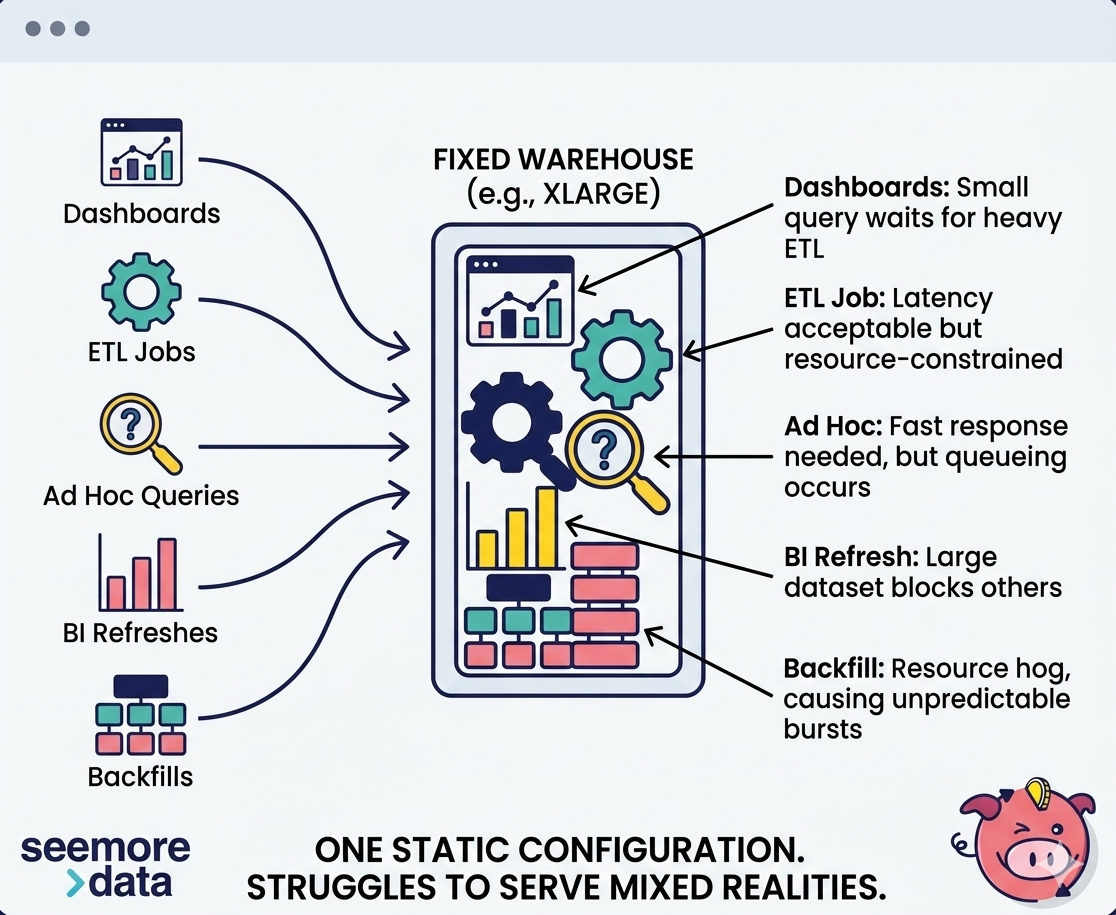
The core problem with warehouse tuning was never that people dislike t-shirt sizes. The real problem was that static warehouse choices were always a bad fit for dynamic workloads.
- A dashboard warehouse is rarely just a dashboard warehouse.
- An ETL warehouse is rarely just ETL.
- A team warehouse almost always becomes a mixed warehouse over time.
Small metadata-heavy queries, heavy joins, transformation jobs, ad hoc exploration, BI refreshes, retry storms, backfills, end-of-month spikes- they all end up sharing the same compute boundary.
Then, teams try to solve a heterogeneous workload with one number.
That number might be LARGE, XLARGE, or MEDIUM (with a few extra clusters).
But it is still one number trying to represent many different computing realities.
At SeemoreData, we addressed this with SmartPulse, which dynamically optimizes warehouse compute by continuously adjusting configurations to balance cost against SLA requirements.
What Snowflake Adaptive Warehouses Improve
An adaptive warehouse is not a minor UI change. It is a meaningful architectural improvement.
If the platform can inspect query behavior and allocate compute more intelligently than a human team doing static sizing, that should reduce a large class of operational mistakes:
- Over-sizing everything because a few queries are heavy.
- Under-sizing everything because finance is watching the bill.
- Using one warehouse shape for workloads that should never have been grouped in the first place.
- Constant manual tuning around bursts, queues, and user complaints.
In that sense, Adaptive Warehouses are not just about convenience; they are an attempt to move compute management one layer up the stack.
That matters.
Because historically, as systems become more dynamic, low-level manual tuning becomes less useful, not more.

But here is the part that matters even more
A better interface is not the same thing as a solved optimization problem. Adaptive removes knobs. It does not remove tradeoffs.
That distinction is critical.
Even in the adaptive model, someone still has to answer questions like:
- What is the largest query I am willing to accelerate aggressively?
- How much burst throughput am I comfortable allowing?
- Which workloads are latency-sensitive?
- Which are budget-sensitive?
- What queueing behavior is acceptable?
- What spend volatility is acceptable?
- What happens when one team wants speed and another team owns the budget?
Those are still engineering questions. Adaptive Warehouses reduce some configuration burden, but they also introduce a new set of decisions. The complexity does not disappear; it shifts.
With standard warehouses, teams managed computing mechanically.
With adaptive warehouses, teams manage compute semantically.
That is better. But it is still management.
At SeemoreData, our goal is to make warehouse configuration truly fire-and-forget. We believe Adaptive Warehouses, while introducing a new set of configuration questions, will help us move one step closer to fulfilling that vision.
This is where Snowflake Adaptive Warehouses can get confusing
There is a temptation to describe Adaptive Warehouses as the moment warehouse management became “automatic.”
That is not right!
As discussed above, what became automatic is the low-level compute selection. What did not become automatic is the policy problem. That policy problem is still very real.
- You still need to define the boundaries of acceptable performance.
- You still need to constrain spending behavior.
- You still need to understand which workloads deserve protection and which ones can wait.
- You still need to reason about production behavior, not just demo behavior.
And that last point matters a lot. In production, the edge cases arrive.
- Burst traffic arrives.
- Workloads collide.
- Budgets get tested.
- Latency expectations become political.
- Chargeback becomes messy.
- One rogue job teaches everyone what “automatic” actually means.
That is where the engineering story starts.
The current blind spot
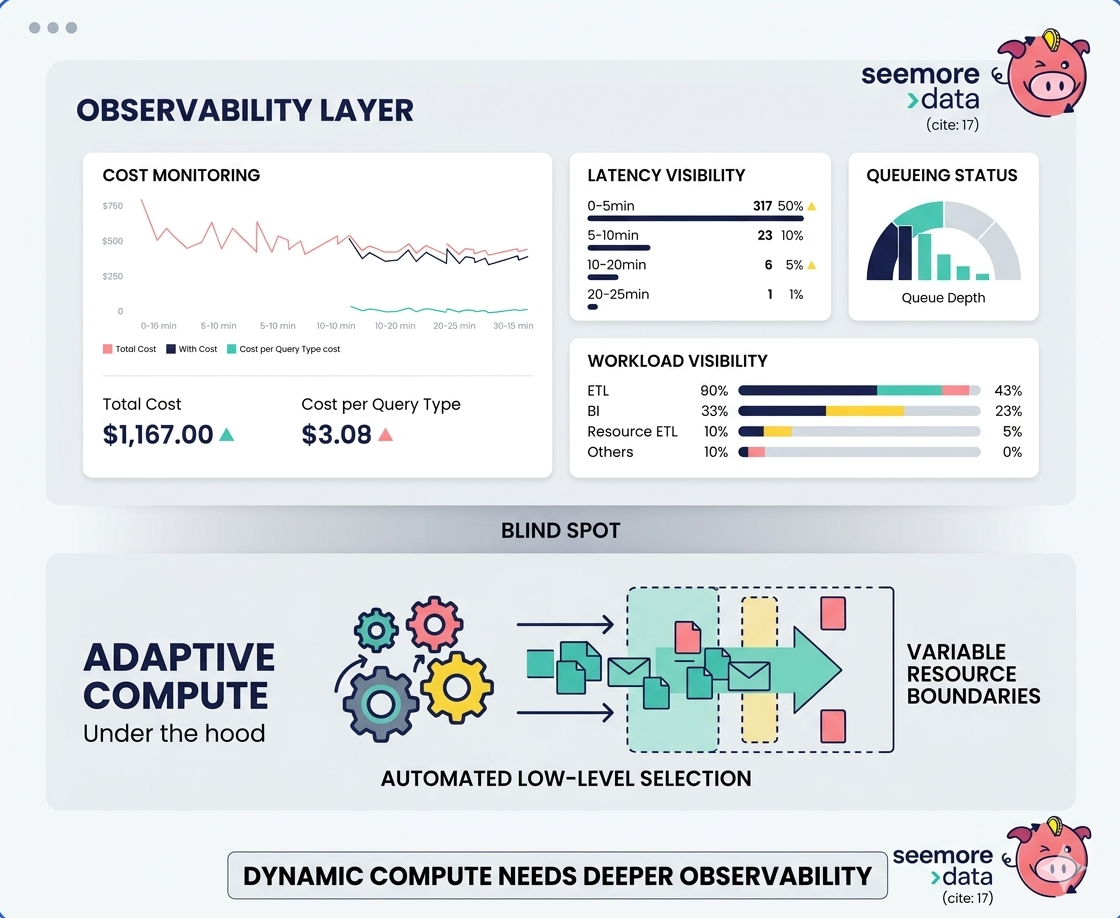
The hardest part of evaluating Adaptive Warehouses right now is not whether the idea is good.
The idea is good.
The hardest part is whether teams can observe and reason about the system well enough once it is live.
When a platform becomes more dynamic internally, the burden on observability goes up, not down.
If compute shape, concurrency behavior, and resource allocation are happening behind a more abstract control surface, then teams need better visibility into what the system is actually doing, why it is doing it, and what the cost consequences are.
Otherwise, the user experience becomes: This feels easier to operate, but harder to fully reason about.
That may still be a net win, but it is not the same as full control. And for engineering teams, trust always depends on explainability.
My take
Snowflake Adaptive Warehouses are an important step forward. They matter because they acknowledge a deeper truth:
Static warehouse management is a weak interface for dynamic data systems.
That is the real idea here.
Once you see it that way, the broader direction becomes clearer. The data stack is moving away from manual infrastructure tuning and toward policy-driven execution.
That is much bigger than warehouses.
- It shows up in optimization.
- It shows up in orchestration.
- It shows up in governance.
- It shows up in observability.
And increasingly, it shows up anywhere a human is still trying to manually manage a system whose behavior is already too dynamic for manual control.
Adaptive Warehouses are one expression of that trend. A good one. SeemoreData’s SmartPulse is another.
I think the real challenge is no longer choosing the right warehouse size. The real challenge is defining the right operating policy for a system that can make more decisions on its own.
It doesn’t necessarily mean less engineering. It means a different kind of engineering. That is exactly why this matters.
FAQ
What is Snowflake Adaptive Compute?
Snowflake Adaptive Compute is a workload-aware compute service that automatically allocates resources for queries. Warehouses created with it are called Adaptive Warehouses.
What are Snowflake Adaptive Warehouses?
Adaptive Warehouses are Snowflake warehouses that run on Adaptive Compute instead of the fixed standard warehouse model. They are designed to reduce manual infrastructure tuning by letting Snowflake adjust compute behavior automatically.
Do Adaptive Warehouses eliminate Snowflake warehouse optimization?
No. Adaptive Warehouses reduce manual sizing and configuration, but teams still need to define acceptable cost, latency, throughput, and workload priorities.
How is Adaptive Compute different from traditional Snowflake warehouse tuning?
Traditional tuning requires teams to choose warehouse size, scaling behavior, and other settings directly. Adaptive Compute shifts that model toward workload-aware resource allocation handled by Snowflake.
Why are static warehouse settings a poor fit for dynamic workloads?
Static settings force mixed workloads to share one compute profile even when query types, concurrency, and latency requirements vary widely. That mismatch is a common source of inefficiency and performance tradeoffs.
What decisions do teams still need to make with Adaptive Warehouses?
Teams still need to decide how much performance headroom to allow, what queueing behavior is acceptable, which workloads are latency-sensitive, and how much volatility they can tolerate.
Why does observability matter more with Adaptive Warehouses?
When compute allocation becomes more dynamic and abstracted, teams need stronger visibility into system behavior, performance outcomes, and cost impact to understand what the platform is doing and why.
Are Adaptive Warehouses the same as a fully automatic policy solution?
No. Adaptive Compute automates low-level compute selection, but it does not automatically solve policy tradeoffs around budgets, SLAs, workload protection, and business priorities.







