

On May 5th, Snowflake officially rolled out Generation 2 Standard Warehouses (Gen2), a long-anticipated upgrade aimed at improving cost-performance for data-heavy workloads. At Seemore Data, we immediately took this to the field: testing it not in theory, but in live production workloads with our customers.
The early verdict? Gen2 has real potential, but like any optimization effort, results depend on workload characteristics, spillage, and execution patterns.
What is a Gen2 Standard Warehouse?
Overall Gen2 is not a new warehouse type, but rather a new smarter, stronger version of the same STANDARD engine. The key difference is in the hardware that enables leveraging greater capabilities. Gen2 runs on faster hardware (like Graviton3 on AWS), with deeper engine-level optimizations that target exactly the pain points we care about:
- Better DML performance (MERGE, UPDATE, DELETE)
- Faster table scans and joins
- Improved concurrency handling
- Lower spin-up latency
- Smarter parallelism out of the box
No SQL changes needed!
What’s Under the Hood?
Snowflake doesn’t expose all the internals, but here’s what we’ve pieced together from internet sources, open discussions, benchmarks and performance traces:
- Arm Neoverse V1 (Graviton3) CPUs on AWS bring improved IPC, SIMD throughput, and cache efficiency.
- Smarter scheduler internals increase task parallelization and reduce CPU stalls.
- Optimized query execution paths for DML-heavy workloads and large scans.
In short, Gen2 is set to deliver more work per credit, for data pipelines or workloads that strain Gen1. But…and this is important! The cost per node is significantly higher.
What About the Cost? (more expensive, but more work done)
Gen2 warehouses cost more per second:
| Cloud | Gen2 cost multiplier vs Gen1 |
| AWS | 1.35x |
| Azure | 1.25x |
So super important to keep a tight watch on the cost performance ratio. The cost performance ratio will tend to be better for complex and long running queries due to:
- Faster Completion = Fewer Seconds Charged
In one we article we read Timoslav Lisak, a staff engineer from Happening that tested a MERGE involving 3.8 million rows into a 1.75 billion-row table (~5.4 TB), with 1.1M inserts and 2.7M updates., cut runtime by 67% (43 minutes to 14 minutes) and overall cost by 56%, despite being 35% more expensive per hour.
- Better Throughput = Fewer Retries
Complex DML jobs that timeout or fail under Gen1 often succeed smoothly on Gen2, reducing wasted compute on retries or reprocessing.
- Potential to Downsize
Thanks to better hardware and smarter parallelism, you may be able to downsize your warehouse (e.g., from XLARGE to LARGE) while maintaining the same or better performance.
Region & Cloud Availability
Gen2 is generally available, but you’ll only find it in select regions for now:
- AWS:
us-west-2 (Oregon), eu-central-1 (Frankfurt)
- Azure:
East US 2, West Europe
❌ GCP is not yet supported. Plan DR setups accordingly if you rely on multi-cloud replication.
Use this to confirm your current region:
sql
CopyEdit
SELECT CURRENT_REGION();
How to Use It: No Magic, Just SQL
Create a Brand-New Gen2 Warehouse
sql
CopyEdit
CREATE OR REPLACE WAREHOUSE etl_pipeline_gen2
WAREHOUSE_SIZE = MEDIUM
RESOURCE_CONSTRAINT = STANDARD_GEN_2
AUTO_SUSPEND = 60
INITIALLY_SUSPENDED = True
AUTO_RESUME = TRUE;
Migrate an Existing Gen1 Warehouse
sql
CopyEdit
ALTER WAREHOUSE daily_batch_wh SUSPEND;
ALTER WAREHOUSE daily_batch_wh SET RESOURCE_CONSTRAINT = STANDARD_GEN_2;
ALTER WAREHOUSE daily_batch_wh RESUME;
Important – Gen2 is not available for X5LARGE or X6LARGE. Use XLARGE or downsize to LARGE if needed.
Real-life Use Case: Gen1 vs Gen2
The real challenge is assessing whether a warehouse type can be changed and what the impact will be. A warehouse usually runs multiple types of workloads. Some workloads may be affected and others may not.
Just to test things out one of our customers at Seemore>data changed their Gen 1 warehouse to a Gen2.
The idea behind choosing this warehouse was that it seemed to be an optimal fit because this was a warehouse that ran a lot of heavy queries with merges and a “not so great” spillage distribution.
Distribution before change:
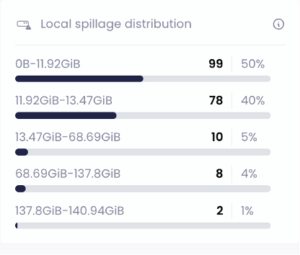
We expected to see a significant change in query runtime distribution and therefore a change in warehouse uptime distribution. Unfortunately this was not the case. Although a slight runtime improvement was seen in some of the queries, the distribution stayed more or less the same and so did the warehouse uptime:
Distribution before change:
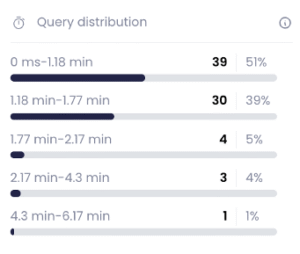
Distribution after change:
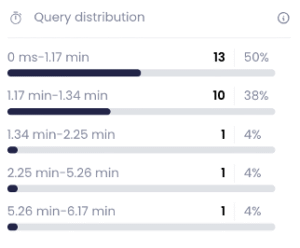
To our surprise there was no improvement in concurrency handling, but queued queries were not a major concern in this case.
Where the changes were significant was the improvement in the p95 query runtime duration from 1.78 -> 1.16 lowering the runtime by 35% improvement.
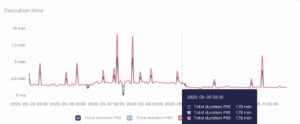
This warehouse still needs to be monitored as some results show that although the p95 queries ran faster with no significant overall change, some days do show an overall rise in total costs of up to 5%.
Impact Summary:
- P95 Runtime Improved: 35% reduction — from 1.78s to 1.16s
- Overall Warehouse Uptime: No significant change
- Daily Cost Volatility: Some days showed up to +5% increase in credits consumed
- Query Runtime Distribution: Slight improvements but not enough to shift the cost curve meaningfully in aggregate
Pro Tips for a Smooth Transition
- Benchmark first. Clone a Gen1 warehouse, switch the constraint, and replay real jobs. Compare query history.
- Watch costs with WAREHOUSE_METERING_HISTORY. Don’t just look at runtime — track actual credit use.
- Mind your DR setup. If your failover regions don’t support Gen2, your pipelines may not resume post-failover.
Next Steps: Simulations at Scale
We’re now launching a structured simulation plan, where we will:
- Replay production workloads on cloned Gen1 and Gen2 warehouses
- Use synthetic and sampled queries (MERGE, UPDATE, SELECT with heavy joins)
- Track query profile, including:
- Query duration distribution
- Warehouse spin-up behavior
- Spillage ratios (temp storage, memory, etc.)
- Compare credit usage patterns across warehouse types and sizes
This will allow us to build cost-performance insights to our customers as to when to use Gen2 and when to keep using Gen1





