

What Are Data Lineage Tools?
Data lineage tools are software applications that map the flow of data across systems and processes, providing a detailed record of its journey from source to destination. They help organizations understand data origins, transformations, and dependencies, enhancing data governance, improving data quality, and supporting impact analysis.
Beyond documentation, data lineage tools often provide mechanisms for ongoing monitoring and real-time updates to these data flow maps as systems evolve. They support root cause analysis by delivering accurate, up-to-date insights about where data came from, how it has changed, and how it supports organizational objectives.
Key features to consider when selecting a data lineage tool include:
- Automated lineage discovery: The ability to automatically scan systems and extract metadata to map data flows.
- Visualization capabilities: Intuitive visualizations of data flows, such as flowcharts or graphs, to aid in understanding.
- Metadata management: Detailed capture of metadata, including sources, transformations, and timestamps.
- Integration with other tools: Seamless integration with various data platforms and tools for a unified view of data flow.
- Impact analysis capabilities: The ability to assess the impact of data changes on downstream systems.
- Data transformations and flows: The ability to track and document every data transformation, such as joins, filters, aggregations, and enrichments.
In this article:
Key Benefits of Data Lineage Tools
Data lineage tools offer several significant advantages that improve an organization’s ability to manage and utilize its data. These tools provide visibility and control over data flows, leading to improved operational efficiency and data reliability.
- Enhanced data governance: By providing a clear picture of data flow, these tools enable better data quality management, compliance with regulations, and overall data governance.
- Improved data quality: Data lineage helps identify the root cause of data quality issues and allows for targeted remediation, ensuring data accuracy and reliability.
- Effective impact analysis: Understanding how data changes impact downstream systems and processes is crucial for making informed decisions and minimizing risks. Data lineage tools enable this analysis.
- Increased data transparency: These tools offer a transparent view of the data lifecycle, fostering trust and confidence in data-driven insights.
- Faster issue resolution: Data lineage enables quick identification and resolution of data-related issues by tracing them back to their source, saving time and resources.
- Better data understanding: By visualizing the data journey, these tools help users understand how data is created, transformed, and used across the organization, promoting data literacy.
Core Features of Data Lineage Tools
Automated Data Lineage Extraction
Through connectors and scanners, data lineage tools parse source code, metadata, and configuration files to detect how data moves and transforms across SQL queries, ETL jobs, data warehouses, and BI platforms. This removes the need for tedious manual documentation that is error-prone and quickly outdated.
Automated extraction scales as systems and data volumes grow, continuously updating lineage maps to reflect infrastructure changes. This real-time visibility ensures that organizations always have an accurate representation of their data ecosystem, forming the basis for reliable governance, troubleshooting, and analytics.
Visualization Capabilities
Strong visualization capabilities transform complex technical mappings into intuitive graphs, matrices, and interactive diagrams. These visual views show data moving between systems, tables, and processes, highlighting sources, destinations, and all intermediary steps. This clarity makes data lineage insights accessible to both technical and non-technical users.
Visualization tools often include filtering, search, and drill-down features for targeted exploration or troubleshooting. By simplifying the complexity of data architectures, these features accelerate both onboarding for new users and day-to-day debugging for experienced engineers, promoting universal data literacy.
Metadata Management
Metadata management is another core capability of data lineage platforms. These tools catalog technical and business metadata—such as data definitions, owners, formats, and quality metrics—across disparate systems. Centralizing metadata makes it easier for users to find, understand, and govern data assets without needing to consult multiple teams or documents.
By integrating metadata management with lineage, organizations not only see how data flows, but also the meaning and context behind each element. This approach supports data stewardship, regulatory compliance, and collaboration.
Integration with Other Tools
Data lineage platforms maximize value by integrating with the broader data ecosystem. They connect to data catalogues, governance solutions, ETL pipelines, BI dashboards, and cloud data platforms, sharing lineage metadata across systems. Integration ensures consistency, enriches business glossaries, and simplifies data operations.
Open APIs and connector libraries support expanding integration options, and many tools offer pre-built plugins for widely used enterprise platforms. This interoperability simplifies deployment, reduces data silos, and accelerates ROI for organizations investing in unified data management.
Impact Analysis Capabilities
Integrated impact analysis capabilities allow organizations to see the ripple effects of any data change. When source fields, transformation logic, or data models are modified, lineage tools highlight every downstream asset that relies on those elements. This mapping accelerates risk analysis, helping teams plan and implement changes more effectively.
Beyond change management, impact analysis supports proactive data quality maintenance. Teams can monitor for unexpected shifts in dependencies, alert stakeholders to potential disruptions, and coordinate updates across data consumers. This insight reduces business risk and improves system stability.
Data Transformations and Flows
Sequential tracing of data transformations and flows is fundamental for modern lineage tools. They detail each step data undergoes—such as filtering, joining, aggregating, or enriching—along every pipeline. Visualizing these transformations enables users to understand exactly which processes have altered their data, which is crucial for auditing and validation.
Maintaining granular records of each flow and transformation ensures that organizations can reproduce results, verify compliance, and meet regulatory requirements. It also gives data teams the confidence to innovate and optimize pipelines, knowing that every adjustment is automatically tracked and documented.
Notable Data Lineage Tools
1. Seemore Data

Seemore Data is a data lineage and observability platform designed to optimize data workflows across modern data stacks. It provides deep lineage insights to help organizations visualize and manage data flows, reduce inefficiencies, and control costs. The platform combines lineage mapping with actionable recommendations to improve operational efficiency and performance.
Key features include:
- Multilayered deep lineage: Offers a multidimensional view of data flows across systems, mapping audit and query logs enriched with ETL metadata and attribution tags for full-stack visibility.
- Cost and performance insights: Delivers real-time recommendations to optimize resource allocation, cut waste, and prevent cost anomalies.
- Anomaly detection: Identifies unusual patterns in data operations, helping teams address issues before they impact workflows.
- Seamless integrations: Connects to leading data warehouses and ETL tools such as Snowflake, BigQuery, Redshift, and Databricks for end-to-end observability.
- Fast onboarding: Designed for rapid deployment, with organizations able to start seeing insights in as little as 30 minutes.
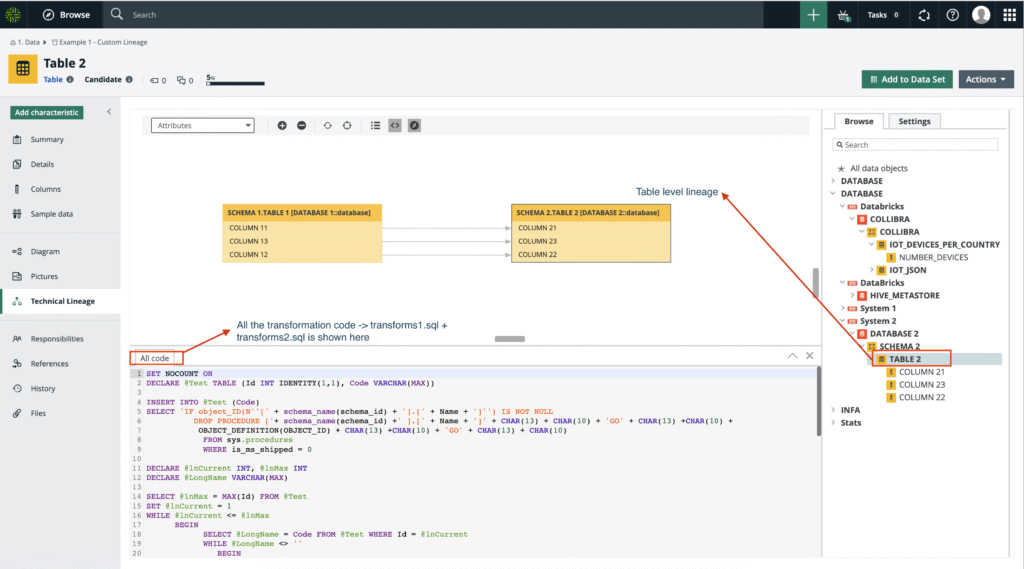
2. Collibra

Collibra is a data governance platform that offers data lineage capabilities, allowing organizations to map and visualize the journey of their data. It provides an automated view of how data flows across various systems, transformations, and business processes.
Key features include:
- Automated data lineage extraction: Automatically maps data’s journey across systems, integrating AI to improve accuracy.
- Root cause analysis: Helps identify and address data issues with a traceable data trail.
- Accelerated data understanding: Provides a comprehensive of data dependencies, business context, compliance requirements, and quality information.
- Faceting and filtering: Uses faceting and filtering to help users find data assets faster and focus on relevant lineage information.
- Inline code context for data transformations: Allows users to drill down into table- and column-level code within lineage diagrams.
3. Alation
![]()
Alation is a data lineage tool intended to simplify data flow visualization while improving collaboration across teams. It provides lineage mapping that helps organizations understand data flows, relationships, health, and impact, overlaying technical data flows with business metadata.
Key features include:
- Accessible business lineage: Simplifies data flow mapping with easy to understand layers, including data health, trust flags, and business metadata overlays.
- Automated data flow mapping: Automatically maps technical data flows while adding business context.
- Data transparency: Embeds metadata such as data health, policy information, and critical data element indicators into lineage diagrams.
- Impact analysis: Helps organizations understand the potential impacts of data changes, helping reduce the risk of outages.
- Data waste elimination: Identifies and eliminates duplicate reports and processes.
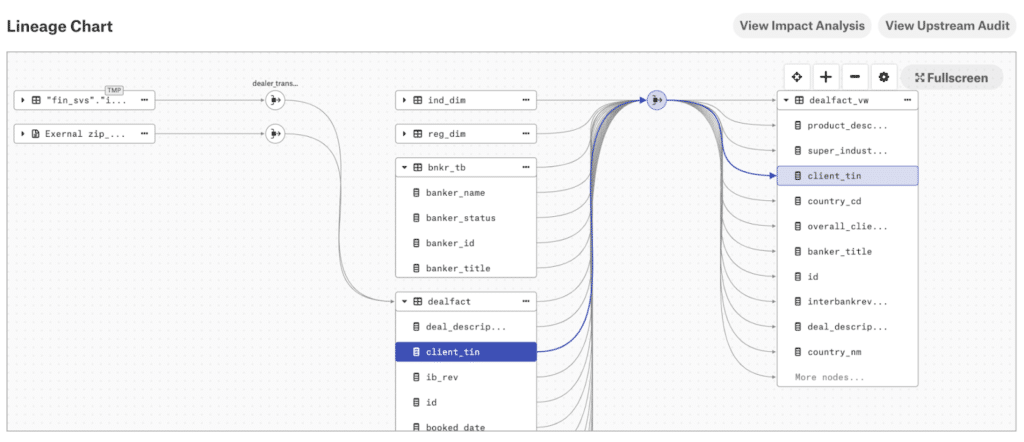
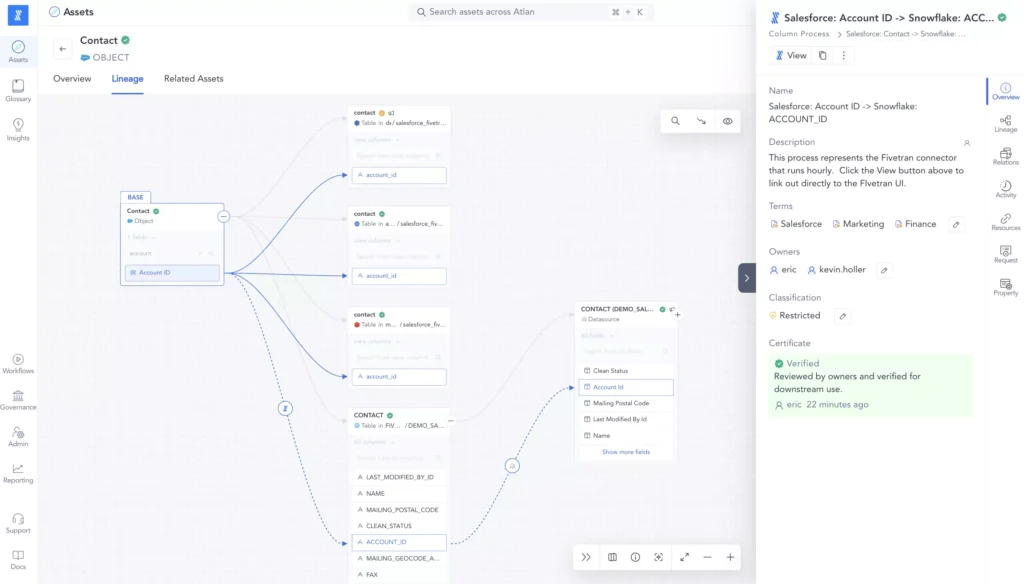
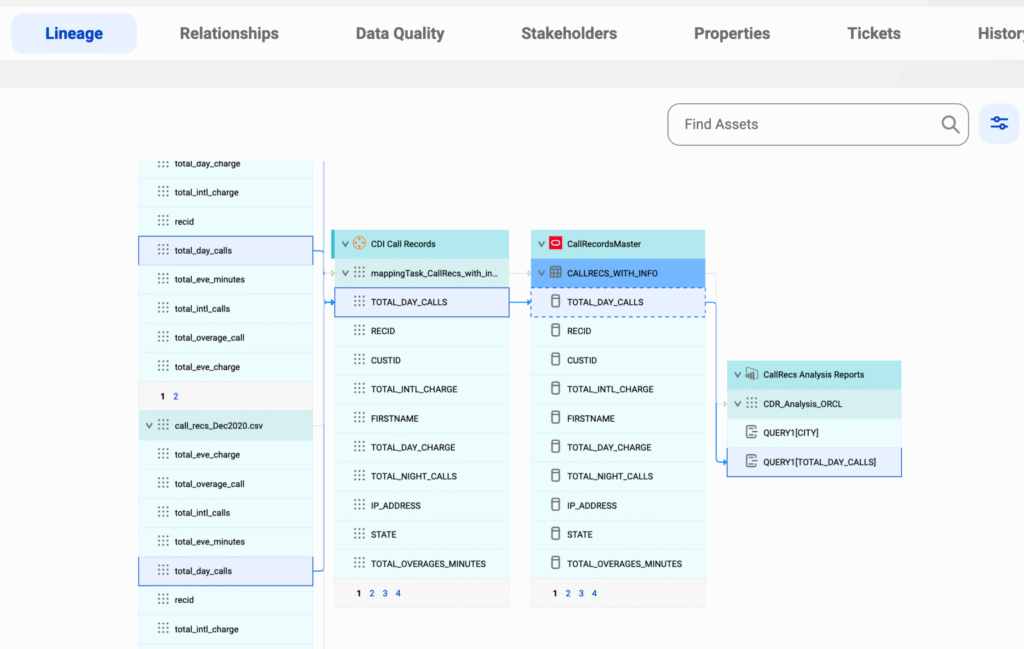
4. Atlan
![]()
Atlan is a data lineage tool for interactive exploration of data flows with integrations into BI tools. It offers an interface that allows users to navigate lineage data at the table or column level. Teams can visualize relationships and dependencies, as well as perform impact analysis directly within the tool.
Key features include:
- Column-level lineage: Provides column-level lineage instead of just table-level relationships.
- Automated SQL parsing: Automatically parses SQL to detect column-level relationships and map dependencies across systems.
- Out-of-the-box integrations: Offers native integrations with data warehouses and BI tools, enabling cross-system lineage.
- Open API for custom integrations: Supports building on top of open APIs, allowing users to bring in additional data products.
- Interactive UX: Provides a Figma-like user experience with controls for exploring data lineage, zooming out for overview, and personalizing views.
5. Informatica

Informatica is a data lineage tool intended to provide visibility into data flows, enabling organizations to build trust, ensure compliance, and drive better decision-making. It uses cloud-native solutions to automate and visualize data lineage, helping teams understand the journey of data from its source to its destination.
Key features include:
- Automated data lineage extraction: Automatically extracts and visualizes data lineage across data pipelines, providing full or summary views of data movement.
- Code parsing for data transformations: Derives lineage from SQL scripts, stored procedures, and AI/ML code to trace data transformations.
- Impact analysis reporting: Tracks data flow from system to column level, providing impact analysis to assess how changes affect downstream data assets.
- End-to-end visibility: Offers transparency into the journey of data, from its origin to consumption.
- Regulatory compliance: Helps organizations comply with regulatory mandates by providing lineage for reporting.
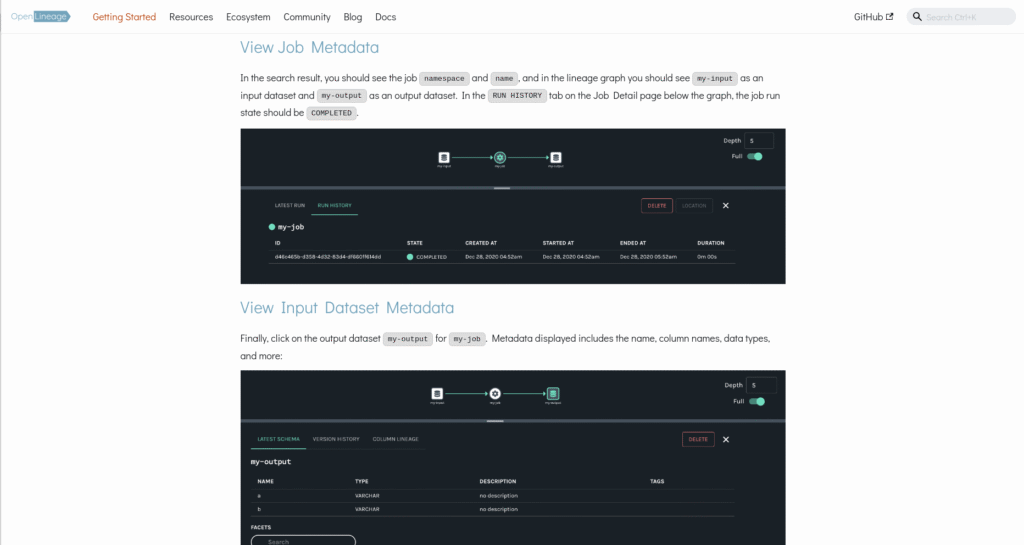
6. Open Lineage
![]()
OpenLineage is an open-source framework for the collection and analysis of data lineage metadata. It provides a standardized API to capture lineage events, enabling integration across different data tools and platforms. OpenLineage focuses on tracking metadata related to datasets, jobs, and runs.
Key features include:
- Open standard for lineage metadata: Defines a universal standard for collecting and analyzing lineage metadata.
- Extensible core model: Uses a core model for jobs, runs, and datasets, allowing custom extensions through user-defined facets.
- API for lineage event capture: Provides a standard API for sending lineage events from various pipeline components (e.g., schedulers, SQL engines, and data warehouses) to a compatible backend.
- Backend integration: Offers a configurable backend to send and process lineage events, enabling integration with different systems and protocols.
- Integration with data tools: Supports integration with data processing frameworks and tools, including Apache Airflow, Apache Flink, Apache Spark, Dagster, dbt, and SQL engines.
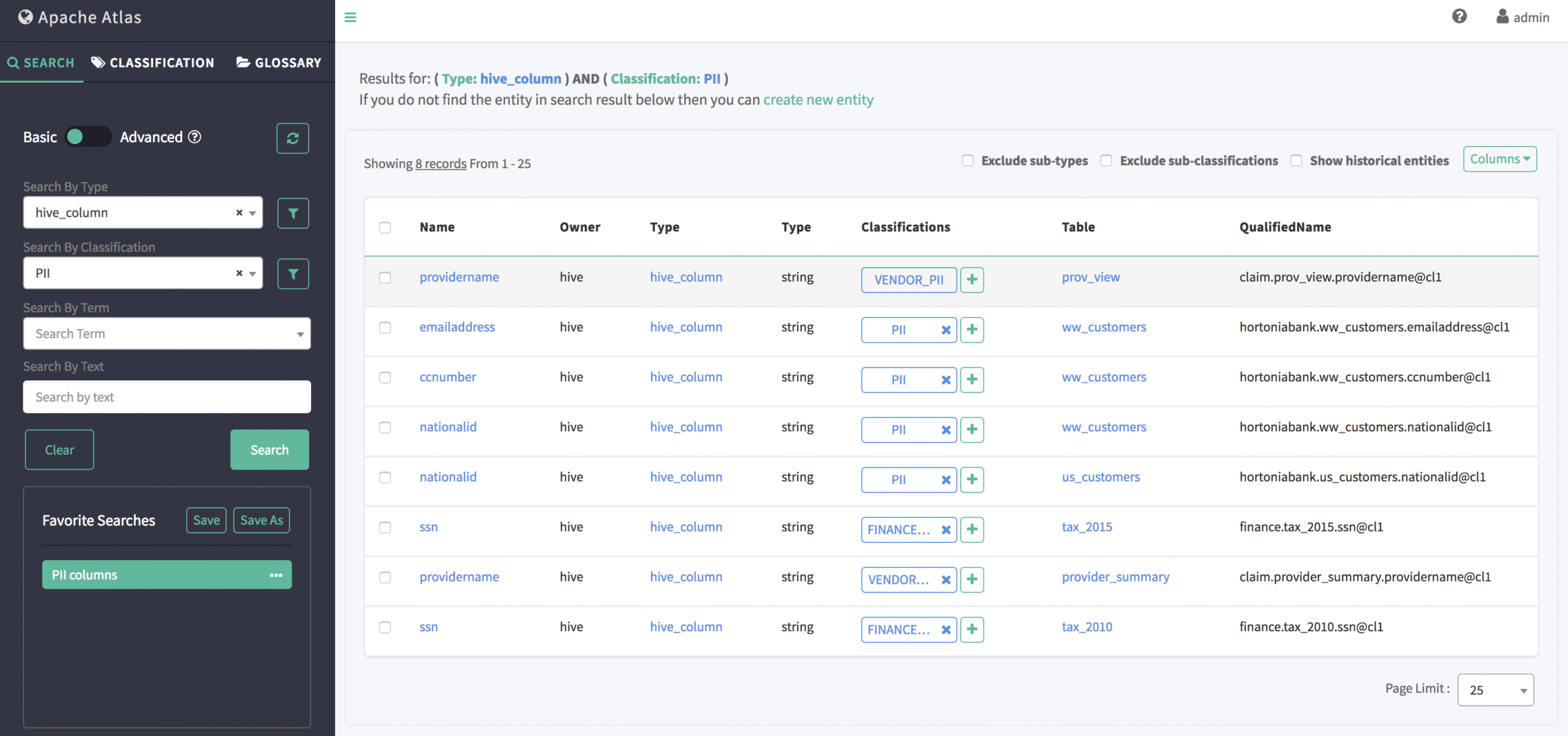
7. Apache Atlas
![]()
Apache Atlas is a metadata management and governance platform to help enterprises manage, classify, and govern their data assets. It enables organizations to meet compliance requirements and provides integration with Hadoop and the broader data ecosystem.
Key features include:
- Metadata management: Supports pre-defined metadata types for both Hadoop and non-Hadoop environments, with the ability to define new metadata types.
- Classification and tagging: Can create and apply classifications such as PII, DATA_QUALITY, and SENSITIVE, enabling better data discovery, security, and compliance.
- Lineage visualization: Provides a user interface for visualizing data lineage, allowing users to track the movement and transformation of data across processes. REST APIs are available for programmatic access and updates to lineage data.
- Search and discovery: Includes search capabilities with a SQL-like domain-specific language (DSL) for querying entities by type, classification, attribute, or free-text.
- Security: Implements security controls over metadata access, allowing authorization of entity instances and operations (such as adding, updating, or removing classifications).
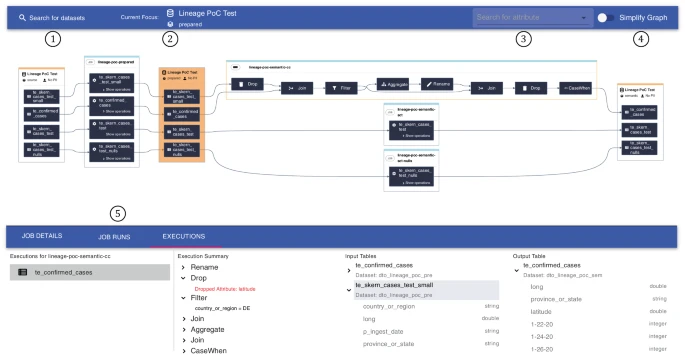
8. Spline
![]()
Spline is an open-source data lineage tracking solution for data processing frameworks like Apache Spark. It provides a way to capture and visualize data lineage across various stages of data processing, enabling data engineers and analysts to track the flow of data, its transformations, and dependencies within the pipeline.
Key features include:
- Integration with data processing frameworks: Integrates with Apache Spark and other data processing frameworks, automatically capturing lineage information during the execution of Spark jobs.
- Producer and consumer APIs: Provides REST and Kafka-based producer APIs for sending lineage events and consumer APIs for retrieving and processing lineage data.
- Web-based user interface: Features a simple user interface for viewing and navigating data lineage.
- Versioning and compatibility: Follows semantic versioning for the application API to ensure backward compatibility. The database schema versioning is separate, indicating when the schema was introduced but does not follow semantic versioning principles.
- Support for Docker containers: Spline can be built and run within Docker containers.
Conclusion
Data lineage tools play a critical role in modern data management by providing end-to-end visibility into how data moves, changes, and supports business processes. They help organizations maintain control over complex data ecosystems, meet regulatory requirements, and foster trust in analytics and AI initiatives.
By enabling teams to trace dependencies and transformations, these tools support proactive governance, faster troubleshooting, and better-informed decision-making across the enterprise.





