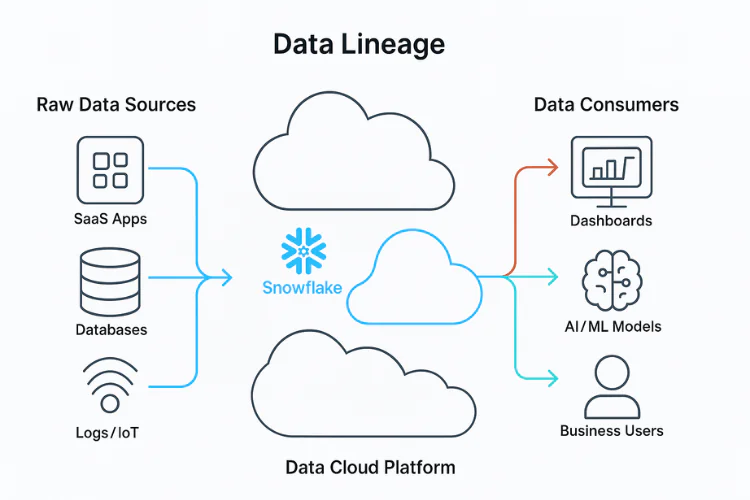
What Is Data Lineage?
Data lineage is the process of tracking and visualizing the flow of data through an organization’s systems. It maps the entire lifecycle of data — from its origin, through the transformations it undergoes, to its final destination. This includes tracing data sources, intermediate processing steps (such as data cleansing or enrichment), and how the data is ultimately consumed in reports, dashboards, or machine learning models.
Lineage diagrams typically show how data fields in a target system (like a BI tool) are derived from fields in source systems (like databases or APIs). This visibility helps data teams understand dependencies and how changes in one part of the data pipeline can affect downstream systems.
In this article:
- Key Benefits of Data Lineage
- How Data Lineage Works
- Data Lineage vs. Data Provenance vs. Data Governance
- Data Lineage Use Cases and Examples
- Key Techniques in Data Lineage with Code Examples
- Challenges in Data Lineage
- Key Features of Data Lineage Tools
- 5 Data Lineage Best Practices
Key Benefits of Data Lineage
Data lineage helps teams understand where data comes from, how it’s transformed, and where it goes. This visibility improves data quality, speeds up troubleshooting, and supports better decision-making.
- Improved data quality and trust: Knowing where data comes from and how it has been transformed allows teams to identify and correct errors at their source. This transparency builds trust in the data being used for analysis and decision-making.
- Faster root cause analysis: When issues arise—such as broken dashboards or incorrect metrics—lineage helps teams trace the problem back to its origin quickly. This reduces downtime and improves incident response times.
- Easier impact analysis for changes: Before modifying a data pipeline or schema, lineage shows which downstream systems and reports rely on the affected data. This prevents unintended disruptions and supports better planning for changes.
- Enhanced regulatory compliance: Lineage helps organizations meet data governance and compliance requirements (e.g., GDPR, HIPAA) by showing how personal or sensitive data moves across systems, where it’s stored, and who accesses it.
- More efficient collaboration: Lineage enables better coordination between data engineers, analysts, and business users. By providing a shared understanding of how data flows and transforms, it reduces miscommunication and accelerates development cycles.
How Data Lineage Works
Data lineage works by collecting metadata from various systems involved in data processing and integrating this information to create a map of data flow. There are several approaches to generating lineage, including manual documentation, parsing code (like SQL or ETL scripts), and using automated tools that extract lineage from data catalogs, databases, and orchestration systems.
The lineage process typically involves three key layers:
- Source layer: This includes all systems where data originates, such as databases, files, APIs, or third-party platforms. Metadata is captured about the structure, origin, and refresh frequency of this data.
- Transformation layer: Data often passes through transformation steps—such as filtering, joining, or aggregation—before it reaches its end use. Lineage tools trace these operations by parsing SQL queries, etl logic, or data pipeline configurations to determine how fields are altered.
- Consumption layer: This layer covers where and how data is used: dashboards, reports, machine learning models, or exports. Mapping these endpoints shows how upstream changes can impact final outputs.
Modern data lineage tools also support column-level lineage, which shows transformations at a field level, and cross-system lineage, connecting data flow across tools like Snowflake, dbt, Airflow, and Tableau. Lineage maps are often visualized as interactive graphs, helping users explore dependencies, track the flow of fields, and assess data quality risks across the pipeline.
Data Lineage vs. Data Provenance vs. Data Governance
While data lineage, data provenance, and data governance are closely related concepts in the field of data management, each serves a distinct purpose:
Data lineage focuses on tracking how data moves and transforms across systems. It maps the path of data from source to destination, including all intermediate steps. The goal is to understand dependencies, transformations, and usage across the data lifecycle.
Data provenance refers to the detailed history of a data element, documenting its origin and every process it has undergone. Provenance emphasizes traceability and auditability, capturing information such as who made changes, when they were made, and what tools were used. It’s often used in highly regulated environments where data integrity and authenticity are critical.
Data governance is the broader discipline that defines how data is managed, secured, and made available across an organization. It encompasses policies, roles, standards, and processes to ensure data quality, privacy, and compliance. Data lineage and provenance are key components that support effective governance by providing the transparency and traceability needed to enforce rules and monitor data usage.
In short:
- Data lineage shows how data moves.
- Data provenance records what happened to data.
- Data governance defines how data should be handled.
Data Lineage Use Cases and Examples
Here’s a more detailed look at when organizations might use data lineage.
Traceability in Data Processing
Traceability is essential for understanding the flow and transformation of data across systems. Data lineage enables teams to trace data back to its source, step by step, including all transformations, merges, and filtering operations it undergoes along the way.
In complex data ecosystems, such as those in financial institutions or e-commerce platforms, data often passes through multiple ETL jobs, enrichment processes, and storage layers before reaching reporting tools.
Real-life example
Consider a customer churn dashboard that combines user behavior logs, transactional history, and support ticket data. With lineage, teams can trace each field back to its source, understand how the data was transformed, and validate the logic applied at every stage.
Impact on Data Governance and Security
Data lineage is a central component of data governance strategies. It provides the transparency needed to manage data responsibly, especially when dealing with sensitive or regulated information. By visually mapping how data flows through systems, lineage tools help identify where protected data resides, how it is transformed, and which users or systems access it.
Real-life example
An organization subject to GDPR must demonstrate how customer data, such as email addresses or financial information, is collected, processed, and stored. With lineage, governance teams can quickly generate reports showing the entire lifecycle of such data, from ingestion through storage to consumption in marketing platforms or analytics tools. This visibility ensures that personal data is handled according to policy and regulatory standards.
Root Cause Analysis and Troubleshooting
Data lineage simplifies the process of diagnosing and resolving data issues. When problems arise—like stale data, incorrect aggregations, or failed report updates—lineage helps teams backtrack through the pipeline to find the exact point of failure.
Real-life example
Imagine a scenario where a financial dashboard suddenly displays negative revenue. Instead of manually inspecting multiple scripts and databases, a data engineer can use lineage to trace the calculation path of the revenue metric. The lineage map might reveal that a recent change in an ETL job accidentally excluded refunds, or that a new data source with incorrect formatting was introduced.
Data Quality Management
Maintaining high data quality requires visibility into where and how data anomalies occur. Data lineage provides the context necessary to associate quality issues—such as missing values, duplicates, or incorrect data types—with the relevant stages in the data pipeline.
Real-life example
Consider a BI team that notices a key metric shows a sudden drop in value. Data lineage allows them to check whether the issue originated from incomplete source data, a failed enrichment step, or a recent schema change. This context speeds up resolution and helps prevent similar issues in the future.
Key Techniques in Data Lineage with Code Examples
There are several ways to keep track of data lineage.
Pattern-Based Lineage
Pattern-based lineage uses metadata scanning and heuristics to identify common data flow patterns. It detects lineage based on structural similarities and naming conventions between source and target systems, without parsing the actual transformation logic.
This method is lightweight and useful when transformation logic is not easily accessible (e.g., black-box ETL tools), but it can be less accurate than parsing.
Example
Assume you have two tables:
raw_sales_data and cleaned_sales_data.
If both share similar column names and cleaned_sales_data was created after raw_sales_data, the tool might infer a lineage.
— Source table
SELECT * FROM raw_sales_data;
Target table (created later with similar column names)
SELECT * FROM cleaned_sales_data;
Even without seeing the transformation logic, a lineage tool might infer that cleaned_sales_data is derived from raw_sales_data.
Lineage by Tagging
Tagging-based lineage relies on metadata annotations embedded in data pipelines, scripts, or transformation logic. Developers or tools explicitly tag data elements to record where they came from and how they’re transformed.
This method gives precise control and is helpful in environments where transformations span multiple tools or manual processes.
Example
In an ETL script, you might tag output columns with comments to mark their source and transformation logic.
Create a report table with tagged columns
SELECT
customer_id, — source: crm.customers.id
order_total * 1.2 AS adjusted_total — source: sales.orders.order_total, transformation: add 20% tax
FROM sales.orders;
Lineage tools can extract these tags to create accurate lineage mappings, even across systems.
Parsing-Based Lineage
This approach involves parsing SQL queries, stored procedures, or ETL scripts to directly extract lineage relationships. It’s highly accurate and widely used in modern data environments.
By analyzing the structure and semantics of queries, tools can determine how each column in a target dataset is derived from specific columns in one or more source datasets.
Example
Transformation logic to create a reporting table
INSERT INTO monthly_revenue_summary (month, total_revenue)
SELECT
DATE_TRUNC(‘month’, order_date) AS month,
SUM(order_total) AS total_revenue
FROM sales.orders
GROUP BY DATE_TRUNC(‘month’, order_date);
Here, parsing the SQL reveals that total_revenue comes from sales.orders.order_total, and month is derived from sales.orders.order_date. This lineage can be traced at the column level.
Self-Contained Lineage
Self-contained lineage is embedded directly into the data platform or pipeline tool itself. Systems like dbt or Apache Beam generate and expose lineage metadata as part of their native operation.
These tools track lineage automatically without needing external scanners or parsers, making integration easier and lineage more complete.
Example (in dbt)
A dbt model defines a transformation that is natively tracked:
— models/revenue_summary.sql
SELECT customer_id,
SUM(order_total) AS total_spent
FROM {{ ref(‘orders’) }}
GROUP BY customer_id;
The ref(‘orders’) call links the revenue_summary model to the orders model. dbt automatically records this relationship, and visual tools can display it as part of the data graph.
Challenges in Data Lineage
It’s also important to be aware of the potential challenges involved in maintaining data lineage.
Scalability Issues
As organizations scale their data infrastructure, maintaining accurate and up-to-date lineage becomes more complex. Large enterprises may operate thousands of datasets, hundreds of pipelines, and multiple storage and processing systems. Tracking lineage across this scale requires high-performance tools capable of ingesting, processing, and visualizing metadata continuously.
Performance bottlenecks often emerge when lineage tools must scan massive volumes of code, logs, and metadata. Real-time lineage tracking can strain resources, especially when lineage needs to be recalculated after every pipeline update.
Column-Level Lineage Complexity
Column-level lineage offers granular insight into how individual fields are transformed, but generating it accurately is difficult. It requires deep parsing of transformation logic—often embedded in complex SQL queries, UDFs, or proprietary ETL configurations.
Complications arise with nested transformations, dynamic SQL, or operations that obscure direct relationships between source and target columns (e.g., pivoting or window functions). Tools must not only parse the logic but also understand execution context to build precise mappings. Maintaining column-level lineage over time adds to the complexity, especially in frequently changing environments.
Integration with Existing Systems
Legacy systems, custom pipelines, and a variety of data tools across departments can make integration a major challenge. Many systems lack APIs or emit inconsistent metadata, preventing seamless lineage extraction.
Even when integration is possible, aligning metadata formats, terminologies, and data models requires significant effort. Organizations must often build custom connectors or metadata bridges to unify lineage across tools like Airflow, Informatica, Hadoop, or proprietary platforms.
Key Features of Data Lineage Tools
Modern data lineage tools provide a range of capabilities that help teams understand, manage, and monitor how data moves across complex systems. Here are the key features typically offered:
- Automated metadata collection: Tools automatically ingest metadata from a variety of sources—databases, data warehouses, ETL tools, BI platforms, and data lakes. This eliminates manual tracking and ensures that lineage maps remain up to date with system changes.
- Column-level lineage tracking: Advanced tools support fine-grained lineage by tracking data transformations at the field or column level. This helps identify exactly how outputs are derived from input data, enabling detailed impact analysis and debugging.
- Interactive visualization: Lineage is often displayed using interactive graphs that allow users to explore upstream and downstream dependencies. Users can click on nodes to reveal transformation logic, view metadata, or trace data paths.
- Cross-system lineage support: Many environments use a mix of tools like dbt, Airflow, Snowflake, and Tableau. Good lineage tools integrate across these platforms to provide end-to-end visibility into data flows, regardless of where the data resides or how it’s processed.
- Data quality integration: Some tools integrate with data quality frameworks to flag anomalies and link them back to specific stages in the pipeline. This helps correlate quality issues with transformations or data sources.
- Versioning and change tracking: Lineage tools often track historical versions of pipelines and datasets. This enables users to compare current and past data flows, identify when changes were made, and assess their impact.
- Access control and auditability: Enterprise-grade lineage tools include user access controls, allowing only authorized personnel to view or edit lineage information. They also log access and changes, supporting governance and compliance audits.
- APIs and extensibility: Many tools provide APIs and SDKs for custom integrations, allowing organizations to extend lineage capabilities, feed metadata into other systems, or embed lineage views into custom dashboards.
5 Data Lineage Best Practices
Organizations should implement the following practices to ensure the most effective use of data lineage.
1. Focus on Quality over Quantity
Capturing lineage for every data movement in an organization might seem desirable, but it often leads to cluttered, noisy maps that are hard to use and maintain. Instead, prioritize high-value lineage—cover critical reports, regulatory datasets, and business-essential pipelines where traceability is most needed.
Emphasize accuracy over coverage. It’s better to have precise lineage for fewer assets than incomplete or misleading mappings for everything. Validate lineage outputs against actual transformation logic to ensure they reflect real data flow. Use automation selectively, and invest time in curating lineage where trust and decision-making depend on it.
For example, in a financial institution, lineage for revenue calculations or compliance reports should be precise and regularly reviewed, while lineage for ad-hoc analysis can be deprioritized or managed with lighter metadata.
2. Surface Relevant Lineage Information
Different users need different views of lineage. A data engineer might want to see SQL logic and transformation nodes, while a compliance officer might just need to know where personal data is stored and who accesses it. Designing lineage displays without tailoring to user roles leads to confusion and low adoption.
Build lineage tools that allow users to drill down when needed but start with high-level summaries. Enable filtering by data domain, transformation type, or data sensitivity. Context-aware visualizations that highlight recent changes or anomalies help teams act faster.
For example, an analyst troubleshooting a metric drop should be able to quickly trace upstream dependencies without navigating irrelevant pipelines or technical metadata.
3. Organize Lineage for Clarity
Lineage maps can become complex quickly, especially in environments with hundreds of systems and data flows. Without structure, even the most detailed lineage becomes unusable. Organize lineage around business functions, departments, or data domains to make navigation easier.
Use grouping, color coding, and naming conventions to visually separate staging tables, production datasets, and external sources. Leverage tool features like node collapsing, lineage filters, and metadata panels to reduce cognitive load.
For example, organize lineage for a customer churn dashboard by clearly separating behavioral data, transaction logs, and support system feeds. This modular view helps users understand data contributions without sifting through the entire ecosystem.
4. Ensure Right Context Inclusion
Lineage by itself—just arrows between systems—is not enough. Teams need context to interpret what the lineage means and how to use it. This includes business definitions, ownership information, data sensitivity, update frequency, and transformation logic.
Enrich lineage data with metadata from catalogs and governance platforms. Provide links to documentation, explain complex transformation steps, and clarify ownership for each dataset. This contextual layer makes lineage not only more informative but also actionable.
For example, knowing that a field was derived from a deprecated data source or is maintained by another team can prevent errors and speed up collaboration. Without context, lineage might raise more questions than it answers.
5. Scale Lineage to Meet Business Needs
Lineage programs must grow alongside the business. Start with critical pipelines and expand coverage as tools and teams mature. Trying to map every pipeline from day one is often unsustainable and leads to poor user experiences.
Choose tools that support incremental lineage updates, scalable metadata processing, and cross-system integration. Define a roadmap to gradually add systems and improve lineage granularity—from table-level to column-level as needed.
As data volumes increase, automate lineage extraction and build governance workflows around it. Regular reviews and metadata refreshes help keep lineage current. A phased, scalable approach ensures that lineage continues delivering value without becoming a maintenance burden.